Time Complexity ,Space Complexity(조사중), 시공간복잡도
매우 주관적인 포스트로서 사실과 다를수도 있습니다. 개인적인 정리 차원입니다.
시공간 복잡도
여러 프로그래밍에 중요한 시공간 복잡도에 대하여 정리해 보자. 내가 기억하는것과 새로이 알게된것을 작성해 보았다. 우선 이를 설명하기 이전에 알고리즘을 정리해야 한다.
알고리즘
알고리즘은 수학과 컴퓨터 과학, 언어학 또는 관련 분야에서 어떠한 문제를 해결하기 위해 정해진 일련의 절차나 방법을 공식화한 형태로 표현한 것, 계산을 실행하기 위한 단계적 절차를 의미한다. 알고리즘은 연산, 데이터 진행 또는 자동화된 추론을 수행한다. Wikipedia
위키피디아 에서는 위와 같이 알고리즘을 설명하고 있다.
보통 수열에서 아래와 같은 것을 본적이 있다.
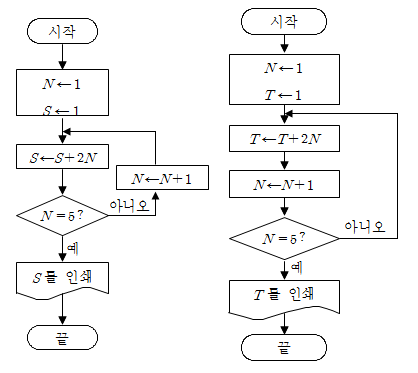
이런것도 알고리즘이다. 위의 수열대신 우리는 조건문과 다른 함수라던지 콘솔을 이용하면 그것이 바로 프로그래밍상에서 알고리즘이 된다. 다만 그림으로 제공해 주지 않는다. 코드로 제공해 준다. 길찾기 알고리즘인 다잌스트라 알고리즘, 소수찾기 알고리즘 등 여러 유명한 알고리즘이 존재하니 찾아보는것도 유익하다. 여튼 내가 주목한 알고리즘이라는것은 주어진 문제를 해결하기위한 방법을 코드로 표현한것 정도? 그래서 만약 내가 길찾는 알고리즘을 코딩했다고 하자. 근데 이 알고리즘은 그래프를 이용하기대문에, 배열로만(가정), 그것도 행렬로 모든것을 표현했다고 생각하자. 심지어 가중치도 표현했다고 가정하고

이런 데이터를 완성했다고 하면, 이를 코딩상으로 만들어 내면 이중 배열을 사용해야 한다. 근데 지금은 7 X 7 행렬이니 49칸만 만들면 되지만 만약 n이 7이 아닌 100개 혹은 만개 이상이라면? 아무리 배열이 인덱스에 접근하기 쉽더라고 만만히 볼것이 아니다. 배열은 통상적으로(일부 언어 제외) 연속된 메모리 공간을 필요로 한다. 이에 배열속에 배열을 선언해서 2차원 배열을 선언하게 된다면 필요한 공간은 n2 X 개당 필요한 공간(대략 4byte이라 가정) 마약 n =1000이라고 하면 4000000byte = 39,062.5KB = 약 38MB 의 메모리 공간이 연속으로 필요로 하며, 저기서 일부의 데이터를 변조 하려하면 뒤에 정리하겠지만, 끔찍하게 느릴수 있다.
저 공간이 별거 아닌것처럼 보이지만, 클라이언트가 천명 단위일리가? 게다가 클라이언트에서 필요한 정보가 한두개가 아닐것이며, 4byte 이상으로 필요한 경우를 따지면 매우 무거운 프로그램이 되지 않을까 싶다. 여기에 프로그램의 램사용 + OS의 램 사용 등을 필요하면저 프로그램은 메모리를 먹어치우는 메모리 헝그리 앱이 되지 않을까? 그러므로, 메모리를 효율적으로 사용하고, 프로그램의 동작시간도 줄이기 위해서 시공간 복잡도는 최대한 줄이는것이 중요하다고 생각한다. 개발자들은 1분 1초라도 빠르게 돌아가는것이 중요하며, 리소스도 작게 먹어 가벼운것이 좋다. (개인적으로 토이 프로그램을 만들때 스택 오버플로우 문제를 올리며 코드를 같이 올린적이 있다. 한 외국 프로그래머가 니 램효율똥망이라고 짜증을 부린이유가 되지 않을까? 그때 프로그램은 필요한거 같은거를 전부 메모리에 올려놓고 절대 해제하지 않고 있었다.) *개인적인 궁금중 만약 리얼타임 프로그램이 저렇게 만들지는 않겠지만, 혹시 저렇게 만들어진다면? -현재 생각 : 리얼타임이 리얼타임이 아니게 될지도? 딜레이가 심각하지 않을까? 그러므로, 이런 이차원 배열은 웬만해서는 하지 않는것이 좋을것 같다.
참 위에서 내가 느릴수 있다고 말을 했는데, 이는 배열의 특성과 관련이 있다. 배열은 (일부 언어 제외) 연속된 공간을 할당하게 되는데, 이때문에 특정 인덱스를 찾는것은 매우 쉽고 빠르지만, 만약 중간의 것을 삭제하거나, 추가해서 배열을 수정하는 경우에는 말이 달라진다. 끝에것을 추가/삭제하는 것은 매우 간단하다. 그냥 마지막 데이터를 추가/삭제 하면 된다. 하지만 배열의 처음,중간에 추가/삭제하려하면 일부 데이터를 삭제/추가하고, 배열의 중간부터 빈공간이 없게끔 다시 배열을 수정해야한다. 이때문에, 만약 처음의 데이터를 삭제, 추가하려고 하면 배열의 나머지에 대하여 그 데이터에 접근해서, 위치를 조정해야 한다. (0번 인덱스 삭제) ->1~n번 인덱스를 앞으로 옮김 즉 1초에 1개의 작업을 할수 있다면 n의 시간이 걸릴것임. 하지만 배열은 특정 인덱스에 접근은 매우 쉬워서, 단 한번의 명령으로 바로 접근이 가능하다. 즉 1의 시간이 걸린다.
빅-오 표기법
이런 시간들을 표현하기 위해 빅-오 Big(O) 표현법을 사용한다.
빅-오 표현법은 알고리즘, 프로그램, 함수에 대하여 가장 큰 시간을 필요로 하는 코드가 필요로 하는 시간을 기준으로 작성된다
만약 내가 짠 프로그램이 2차원 배열, 1차원 배열, 콘솔 출력 이렇게 작성했다고 하면
각각 n2의 시간, n의 시간, 1의 시간이 필요하다. 즉 O(n^2 + n + 1)인데, 프로그램의 동작 시간에 매우 큰 영향을 주는것은 이차원 배열이다.
그러므로 프로그램상 이차원배열이 가장 오래걸리게 되니 나머지 배열과 콘솔 출력은 프로그램의 전체 시간에 영향이 적다. 그러므로 빅-오는 이 두가지의 시간을 삭제한다. 즉 O(n2)이라 표현한다.
이는 가장 최악의 경우를 생각하는것과 같다. 특징으로는 상수의 시간이 걸리면 O(1), 1차원 배열을 사용하는 경우는 갯수 상관없이 O(n), 이차원 배열을 사용하는 경우는 O(n2)이 된다.
가장 큰 시간을 필요로 하는것을 적으며, 갯수 상관없이 가장 큰 영향을 미치게 되는 요소의 최악의 경우를 작성하면 된다.
이런 빅-오들의 결과값들의 특징은 다음과 같다.
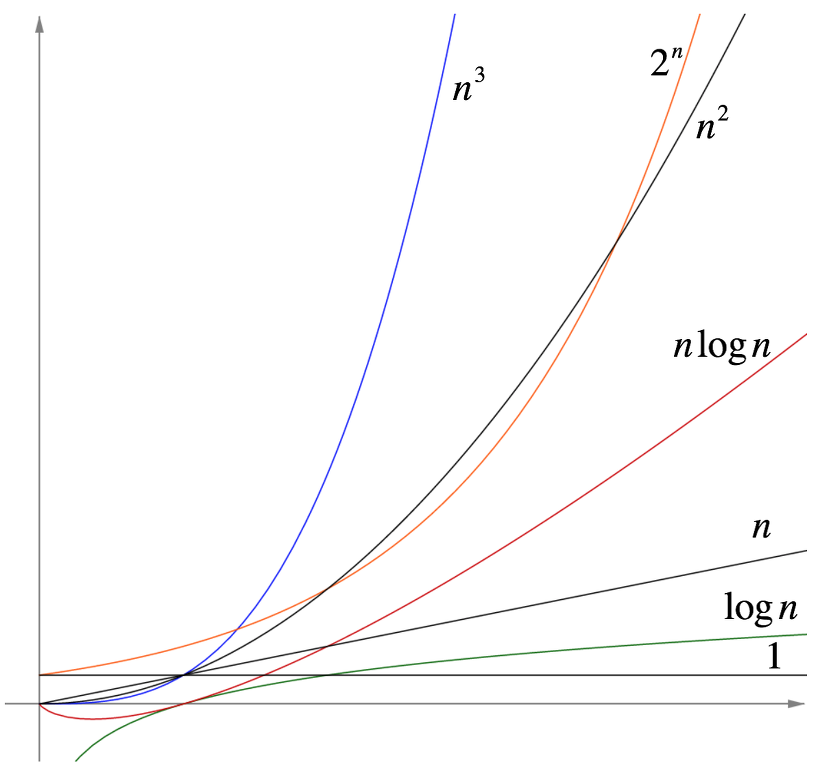
O(1) - 상수, n의 크기 상관없이 필요로 하는 시간이 같다. (콘솔 로그) O(n) - 필요한 n에 따라 시간도 선형으로 필요해 진다.(ex 배열) O(log N) - n보다 더 빠른 동작시간. 이진트리같은 경우 여기에 해당한다. O(N log N) - 이진트리같은 것에서 추가적으로 정렬을 하는경우 여기에 해당한다. 소팅 알고리즘이 해당 되는듯. O(n2),그이상 - n이 증가할수록 필요로 하는 시간이 치솟는다. (이차원 배열 그 이상)
이를 지금까지 공부한 자료구조에 대입하면 다음과 같은 결과를 가지게 된다.
- 링크드 리스트 헤드에서 삭제 O(1), 리스트 어딘가에서 삭제(제일 끝인 경우) - O(n) 헤드에 새로 노드를추가하는 경우 O(1), 노드 찾기O(n) 따라서 링크드 리스트는 O(n)을 가지게 된다.
- 해시 테이블 해시펑션에 다르겠지만, 해시 테이블 자체를 보면 배열을 이용하며, 이중 index로 해시테이블에 접근을 하는것만 생각하자면 O(1)이다.
- 그래프 노드 배열과 엣지 행렬(객체 내 배열로) 두가지 혼용하는 경우를 생각했다. 노드 추가 - 노드배열 맨뒤에 넣으면 된다. O(1) 노드삭제 - 최대 모든 n에 대하여 접근해야한다. O(n), 엣지 추가 객체의 각 노드의 배열에 접근하여 추가해야 한다. O(2) = O(1) 엣지 삭제 각 노드의 행렬배열에 접근하여 작업을 해야한다. 최대 모든 n에 대하여 접근해야하므로 O(2n) = O(n) 따라서 O(n)의 시간을 가지게 된다.
- 트리 n진 트리의 경우 - 정렬이 되어 있지 않는다면 모든 노드를 탐색해야 할수도 있다. 다만, 트리의 특성상 디바이드-컨커를 사용한다면 logmN의 시간이 걸릴것이다.(m = m진 트리, n은 노드 수) 즉 O(logMN) = O(logN)
- 이진 탐색 트리 균형이 잡혀있지 않다면 링크드 리스트와 같을것이다. 최대 O(n) 균형이 잡혀 있는 경우라면 노드 탐색, 추가의 경우는 log2N만큼 소요될것이다. 하지만 특정 노드의 제거의 경우는 모든 노드들에 대하여 재정렬이 필요하지만, 역시 dvide-conquer를 따라서 해결한다면 O(nlog n). 따라서 O(log N) 혹은 O(nlog n)
공간복잡도
공간복잡도 S(t)는 이와 다를수 있다 내 믿지 못할 기억으로는 메모리 공간의 사용성에 대한 내용이다. 시간 복잡도와 비슷한 부분이 많고, 공간에 대한 부분에 생각하면 편하다. 근데 요즘 메모리 공간이 매우 넓찍한데 의미가 있는지는 모르겠다. (신뢰도가 매우 낮은 정보이다. 거르는게 마음에 편하다) 언듯 보기에는 둘이 비슷하나, 공간복잡도는 힙, 스택 등등을 합쳐서 생각하는것 같다. 더 복잡하네
댓글남기기